This tutorial is adapted from Web Age course Confluent Kafka for System Administrators.
1.1 Building Data Pipelines
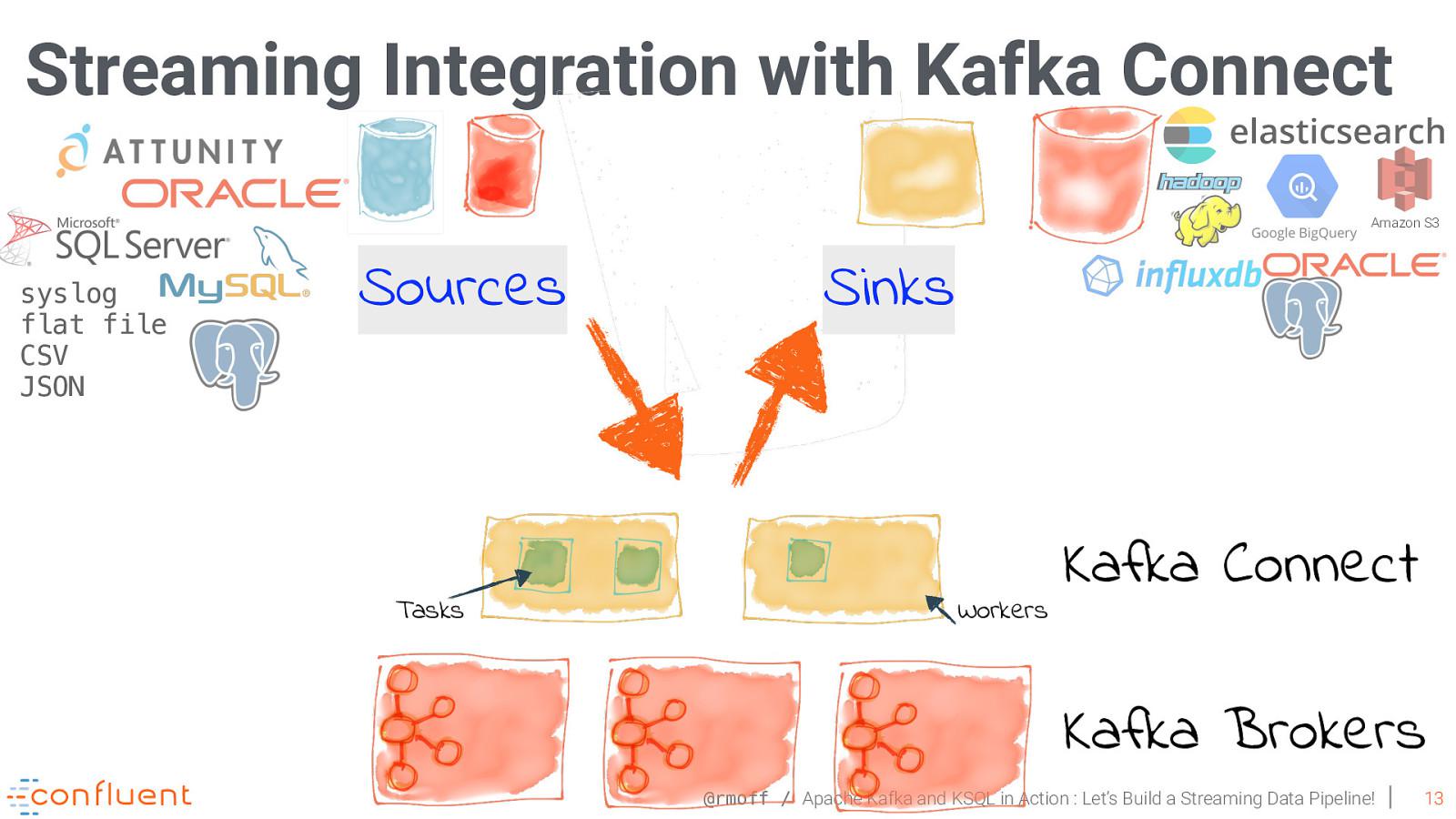
Data pipelines can involve various use cases:
-
Building a data pipeline where Apache Kafka is one of the two endpoints. For example, getting data from Kafka to S3 or getting data from MongoDB into Kafka.
-
Building a pipeline between two different systems but using Kafka as an intermediary. For example, getting data from Twitter to Elasticsearch by sending the data first from Twitter to Kafka and then from Kafka to Elasticsearch.
-
The main value Kafka provides to data pipelines is its ability to serve as a very large, reliable buffer between various stages in the pipeline, effectively decoupling producers and consumers of data within the pipeline.
-
This decoupling, combined with reliability security and efficiency, makes Kafka a good fit for most data pipelines.
1.2 Best Practices for Designing Pipelines
-
Send as much data as possible (all fields/properties).
-
Let consumer applications filter out what they need.
-
When possible avoid processing in the pipeline itself.
-
Use Kafka connect APIs and connectors when interacting with 3rd party data stores.
-
Use producer/consumer clients when interacting with in-house applications.
-
Take advantage of Kafka’s parallelization features to improve throughput and to support scaling.
-
Use schemas to support future changes in data fields and types.
-
Only make use of pipelines when loose coupling is a requirement.
-
Avoid using pipelines when tight coupling is required.
1.3 Considerations When Building Data Pipelines
-
Timeliness
-
Reliability
-
High and varying throughput
-
Data formats
-
Transformations
-
Security
-
Failure handling
-
Coupling and agility
1.4 Timeliness
Good data integration systems can support different timeliness requirements for different pipelines. Kafka makes the migration between different timetables easier as business requirements can change. Kafka is a scalable and reliable streaming data platform which can be used to support anything from near-real-time pipelines to hourly batches. Producers can write to Kafka as frequently as needed and consumers can also read and deliver the latest events as they arrive. Consumers can work in batches, when required, such as run every hour, connect to Kafka, and read the events that accumulated during the previous hour. Kafka acts as a buffer that decouples the time-sensitivity requirements between producers and consumers. Producers can write events in real-time while consumers process batches of events or vice versa. Consumption rate is driven entirely by the consumers.
1.5 Reliability
Systems failure for more than a few seconds can be hugely disruptive, especially when the timeliness requirement is closer to the few-milliseconds end of the spectrum. Data integration systems should avoid single points of failure and allow for fast and automatic recovery from all sorts of failure events. Data pipelines are often the way data arrives in business critical systems. Another important consideration for reliability is delivery guarantees. Kafka offers reliable and guaranteed delivery.
1.6 High and Varying Throughput
The data pipelines should be able to scale to very high throughput. They should be able to adapt if throughput suddenly increases and reduces. With Kafka acting as a buffer between producers and consumers, we no longer need to couple consumer throughput to the producer throughput. If producer throughput exceeds that of the consumer, data will accumulate in Kafka until the consumer can catch up. Kafka’s ability to scale by adding consumers or producers independently allows us to scale either side of the pipeline dynamically and independently to match the changing requirements. Kafka is a high-throughput distributed system capable of processing hundreds of megabytes per second on even modest clusters. Kafka also focuses on parallelizing the work and not just scaling it out. Parallelizing means it allows data sources and sinks to split the work between multiple threads of execution and use the available CPU resources even when running on a single machine. Kafka also supports several types of compression, allowing users and admins to control the use of network and storage resources as the throughput requirements increase.
1.7 Data Formats
A good data integration platform allows and reconciles different data formats and data types. The data types supported vary among different databases and other storage systems. e.g. you may be loading XMLs and relational data into Kafka and then need to convert data to JSON when writing it. Kafka itself and the Connect APIs are completely agnostic when it comes to data formats. Producers and consumers can use any serializer to represent data in any format that works for you. Kafka Connect has its own in-memory objects that include data types and schemas, but it allows for pluggable converters to allow storing these records in any format. Many sources and sinks have a schema; we can read the schema from the source with the data, store it, and use it to validate compatibility or even update the schema in the sink database e.g. if someone added a column in MySQL, a pipeline will make sure the column gets added to Hive too as we are loading new data into it. When writing data from Kafka to external systems, Sink connectors are responsible for the format in which the data is written to the external system. Some connectors choose to make this format pluggable. For example, the HDFS connector allows a choice between Avro and Parquet formats.
1.8 Transformations
There are generally two schools of building data pipelines, ETL (Extract-Transform-Load) and ELT (Extract-Load-Transform).
ETL – it means the data pipeline is responsible for making modifications to the data as it passes through. It has the perceived benefit of saving time and storage because you don’t need to store the data, modify it, and store it again. It shifts the burden of computation and storage to the data pipeline itself, which may or may not be desirable. The transformations that happen to the data in the pipeline tie the hands of those who wish to process the data farther down the pipe. If users require access to the missing fields, the pipeline needs to be rebuilt and historical data will require reprocessing (assuming it is available).
ELT – it means the data pipeline does the only minimal transformation (mostly around data type conversion), with the goal of making sure the data that arrives at the target is as similar as possible to the source data. These are also called high-fidelity pipelines or data-lake architecture. In these systems, the target system collects “raw data” and all required processing is done at the target system. Users of the target system have access to all the data. These systems also tend to be easier to troubleshoot since all data processing is limited to one system rather than split between the pipeline and additional applications. The transformations take CPU and storage resources at the target system.
1.9 Security
In terms of data pipelines, the main security concerns are:
Encryption – the data going through the pipe should be encrypted. This is mainly a concern for data pipelines that cross datacenter boundaries.
Authorization – Who is allowed to make modifications to the pipelines?
Authentication – If the data pipeline needs to read or write from access-controlled locations, can it authenticate properly?
Kafka allows encrypting data on the wire, as it is piped from sources to Kafka and from Kafka to sinks. It also supports authentication (via SASL) and authorization. Kafka’s encryption feature ensures the sensitive data can’t be piped into less secured systems by someone unauthorized. Kafka also provides an audit log to track access—unauthorized and authorized. With some extra coding, it is also possible to track where the events in each topic came from and who modified them, so you can provide the entire lineage for each record.
1.10 Security Best Practices
Encrypt data going through pipeline’s that cross network (datacenter) boundaries. This can be done with TLS/SSL. Zookeeper and Kafka Brokers should be located behind the firewall. Require authentication between clients and brokers, between brokers and tools and in between brokers. Restrict read/write access to topics to specific clients. Restrict pipeline modification rights to specific users.
1.11 Failure Handling
It is important to plan for failure handling in advance, such as:
- Can we prevent faulty records from ever making it into the pipeline?
- Can we recover from records that cannot be parsed?
- Can bad records get fixed (perhaps by a human) and reprocessed?
What if the bad event looks exactly like a normal event and you only discover the problem a few days later? Because Kafka stores all events for long periods of time, it is possible to go back in time and recover from errors when needed.
1.12 Coupling and Agility
One of the most important goals of data pipelines is to decouple the data sources and data targets. There are multiple ways accidental coupling can happen:
-
Ad-hoc pipelines
-
Loss of metadata
-
Extreme processing
1.13 Ad-hoc Pipelines
Some companies end up building a custom pipeline for each pair of applications they want to connect. For example:
- Use Logstash to dump logs to Elasticsearch
- Use Flume to dump logs to HDFS
- Use GoldenGate to get data from Oracle to HDFS
- Use Informatica to get data from MySQL and XMLs to Oracle
This tightly couples the data pipeline to the specific endpoints and creates a mess of integration points that requires significant effort to deploy, maintain, and monitor. Data pipelines should only be planned for systems where it’s really required.
1.14 Loss of Metadata
If the data pipeline doesn’t preserve schema metadata and does not allow for schema evolution, you end up tightly coupling the software producing the data at the source and the software that uses it at the destination. Without schema information, both software products need to include information on how to parse the data and interpret it. For example: If data flows from Oracle to HDFS and a DBA added a new field in Oracle without preserving schema information and allowing schema evolution, either every app that reads data from HDFS will break or all the developers will need to upgrade their applications at the same time. Neither option is agile. With support for schema evolution in the pipeline, each team can modify their applications at their own pace without worrying that things will break down the line.
1.15 Extreme Processing
Some processing/transformation of data is inherent to data pipelines. Too much processing ties all the downstream systems to decisions made when building the pipelines. For example, which fields to preserve and how to aggregate data. This often leads to constant changes to the pipeline as requirements of downstream applications change, which isn’t agile, efficient, or safe. The more agile way is to preserve as much of the raw data as possible and allow downstream apps to make their own decisions regarding data processing and aggregation.
1.16 Kafka Connect Versus Producer and Consumer
When writing to Kafka or reading from Kafka, you have the choice between using a traditional producer and consumer clients and using the Connect APIs and the connectors. Use Kafka clients when you can modify the code of the application that you want to connect an application to and when you want to either push data into Kafka or pull data from Kafka. Use Connect to connect Kafka to datastores that you did not write and whose code you cannot or will not modify.Connect is used to pull data from the external datastore into Kafka or push data from Kafka to an external store. For datastores where a connector already exists, Connect can be used by non-developers, who will only need to configure the connectors. Connect is recommended because it provides out-of-the-box features like configuration management, offset storage, parallelization, error handling, support for different data types, and standard management REST APIs. If you need to connect Kafka to a datastore and a connector does not exist yet, you can choose between writing an app using the Kafka clients or the Connect API. Writing a small app that connects Kafka to a datastore sounds simple, but there are many little details you will need to handle data types and configuration that make the task non-trivial. Kafka Connect handles most of this for you, allowing you to focus on transporting data to and from the external stores.
1.17 Summary
-
Kafka can be used to implement data pipelines
-
When designing the data pipelines, various factors should be considered.
-
One of the most important Kafka features is its ability to deliver all messages under all failure conditions.