1.1 What is Spark Shell?
The Spark Shell offers interactive command-line environments for Scala and Python users. SparkR Shell has only been thoroughly tested to work with Spark standalone so far and not all Hadoop distros available, and therefore is not covered here. The Spark Shell is often referred to as REPL (Read/Eval/Print Loop).The Spark Shell session acts as the Driver process. The Spark Shell supports only Scala and Python (Java is not supported yet). The Python Spark Shell is launched by the pyspark command. The Scala Spark Shell is launched by the spark-shell command.
Featured Upcoming
Free Webinars and Whitepapers!
Join our community of 80,000 IT professionals by registering today.
Do Stakeholders Understand You? Three Fatal
Signs It’s Time to Add Archimate to Your Toolbox
Friday, October 29![]()
12:00 to 1:00 PM ET
Three Way to Implement
Data Analytics on Azure
DATE TO BE CONFIRMED![]()
11:00 AM to 12:00 PM ET
Data Engineering & Data Analytics
Upskilling Trends in 2021
Complimentary White Paper![]()
10 Minute Guide
1.2 The Spark v.2 + Shells
-
The Welcome screen of Scala and Python Spark Shells (REPLs)
Scala Spark Shell Welcome Screen
(spark-shell )
SPARK_MAJOR_VERSION is set to 2, using Spark2 Setting default log level to “WARN”.
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Spark context Web UI available at http://sandbox-hdp.hortonworks.com:4040
Spark context available as ‘sc’ (master = local, app id = local-1534860472750). Spark session available as ‘spark’.
Welcome to
/ / / /
_\ \/ _ \/ _ `/ / ‘_/
/ / . /\_,_/_/ /_/\_\ version 2.3.0.2.6.5.0-292
/_/
Using Scala version 2.11.8 (OpenJDK 64-Bit Server VM, Java 1.8.0_171)
Python Spark Shell Welcome Screen (pyspark)
Type in expressions to have them evaluated. Type :help for more information.
scala>
SPARK_MAJOR_VERSION is set to 2, using Spark2 Python 2.7.5 (default, Apr 11 2018, 07:36:10)
on linux2
Type “help”, “copyright”, “credits” or “license” for more information. Setting default log level to “WARN”.
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Welcome to
/ / / /
_\ \/ _ \/ _ `/ / ‘_/
/ / . /\_,_/_/ /_/\_\ version 2.3.0.2.6.5.0-292
/_/
Using Python version 2.7.5 (default, Apr 11 2018 07:36:10) SparkSession available as ‘spark’.
>>
1.3 The Spark Shell UI
When you start a Spark shell, it automatically launches an embedded Jetty web server which starts listening on port 4040.
-
 Subsequently launched shells increment their embedded web servers’ base port by one (4041, 4042, etc.)
Subsequently launched shells increment their embedded web servers’ base port by one (4041, 4042, etc.)

1.4 Spark Shell Options
You can get help on spark-shell and pyspark start-up options by invoking them with the -h flag:
◊ pyspark -h
◊ spark-shell -h
-
-
Note: You can pass a source code fragment to be executed within the started (Scala) Spark Shell using the -i flag
-
You can pass parameters to Spark Shell using the Bash environment variables, e.g.
◊ Set a variable (in a Bash shell session):
-
-
export MYPARAM=VALUE
-
◊ Start a Spark Shell session
◊ Read the value (e.g. inside a Scala Spark Shell session):
-
-
System.getenv(“MYPARAM“)
-
To quit your Scala Shell session (the Scala interpreter), enter :quit
Notes:
The spark-shell and pyspark Spark Shell options are printed when invoked with the -h flag. The list of those options is shown below:
Options:
–master MASTER_URL spark://host:port, mesos://host:port, yarn,
k8s://https://host:port, or local (Default: local).
–deploy-mode DEPLOY_MODE Whether to launch the driver program locally (“client”) or
on one of the worker machines inside the cluster (“cluster”) (Default: client).
–class CLASS_NAME Your application’s main class (for Java / Scala apps).
–name NAME A name of your application.
–jars JARS Comma-separated list of jars to include on the driver and executor classpaths.
–packages Comma-separated list of maven coordinates of jars to include on the driver and executor classpaths. Will search the local maven repo, then maven central and any additional remote repositories given by –repositories. The format for the coordinates should be groupId:artifactId:version.
–exclude-packages Comma-separated list of groupId:artifactId, to exclude while
resolving the dependencies provided in –packages to avoid dependency conflicts.
–repositories Comma-separated list of additional remote repositories to
search for the maven coordinates given with –packages.
–py-files PY_FILES Comma-separated list of .zip, .egg, or .py files to place
on the PYTHONPATH for Python apps.
–files FILES Comma-separated list of files to be placed in the working
directory of each executor. File paths of these files
in executors can be accessed via SparkFiles.get(fileName).
–conf PROP=VALUE Arbitrary Spark configuration property.
–properties-file FILE Path to a file from which to load extra properties. If not
specified, this will look for conf/spark-defaults.conf.
–driver-memory MEM Memory for driver (e.g. 1000M, 2G) (Default: 1024M).
–driver-java-options Extra Java options to pass to the driver.
–driver-library-path Extra library path entries to pass to the driver.
–driver-class-path Extra class path entries to pass to the driver. Note that
jars added with –jars are automatically included in the classpath.
–executor-memory MEM Memory per executor (e.g. 1000M, 2G) (Default: 1G).
–proxy-user NAME User to impersonate when submitting the application.
This argument does not work with –principal / –keytab.
–help, -h Show this help message and exit.
–verbose, -v Print additional debug output.
–version, Print the version of current Spark.
Cluster deploy mode only:
–driver-cores NUM Number of cores used by the driver, only in cluster mode
(Default: 1).
Spark standalone or Mesos with cluster deploy mode only:
–supervise If given, restarts the driver on failure.
–kill SUBMISSION_ID If given, kills the driver specified.
–status SUBMISSION_ID If given, requests the status of the driver specified.
Spark standalone and Mesos only:
–total-executor-cores NUM Total cores for all executors.
Spark standalone and YARN only:
–executor-cores NUM Number of cores per executor. (Default: 1 in YARN mode,
or all available cores on the worker in standalone mode)
YARN-only:
–queue QUEUE_NAME The YARN queue to submit to (Default: “default”).
–num-executors NUM Number of executors to launch (Default: 2).
If dynamic allocation is enabled, the initial number of executors will be at least NUM.
–archives ARCHIVES Comma separated list of archives to be extracted into the
working directory of each executor.
–principal PRINCIPAL Principal to be used to login to KDC, while running on
secure HDFS.
–keytab KEYTAB The full path to the file that contains the keytab for the
principal specified above. This keytab will be copied to the node running the Application Master via the Secure Distributed Cache, for renewing the login tickets and the
delegation tokens periodically.
1.5 Getting Help
In Scala Spark Shell, to get help on a supported command, type in the following command:
:help
-
the :help command prints the related help content and returns
-
In Python Spark Shell, help is only available for Python objects (e.g. modules)
help(object)
Notes:
The following help commands are supported in Scala Spark Shell (invoked by :help Shell command):
All commands can be abbreviated, e.g. :he instead of :help.
Those marked with a * have more detailed help, e.g. :help imports.
:cp <path> add a jar or directory to the classpath
:help print this summary or command-specific help
:history show the history (optional num is commands to show)
:h? <string> search the history
:imports [name name …] show import history, identifying sources of names
:implicits show the implicits in scope
:javap <path|class> disassemble a file or class name
:load <path> load and interpret a Scala file
:paste enter paste mode: all input up to ctrl-D compiled together
:quit exit the repl
:replay reset execution and replay all previous commands
:reset reset the repl to its initial state, forgetting all session entries
:sh <command line> run a shell command (result is implicitly => List)
:silent disable/enable automatic printing of results
:fallback
disable/enable advanced repl changes, these fix some issues but may introduce others. This mode will be removed once these fixes stablize
:type <expr> display the type of an expression without evaluating it
:warnings show the suppressed warnings from the most recent line which had any
1.6 The Spark Context (sc) and Spark Session (spark)
The Spark Context, available for programmatic access through the sc object, is the legacy Spark API object fully initialized when you start a Spark Shell. As of version 2, another way to interface with Spark was added, which is through the spark session object; it is also fully initialized when you start a Spark Shell session.
-
Note:
◊ Only one sc / spark object may be active per your Shell session (which is backed up by a single JVM or Python runtime)
1.7 The Shell Spark Context Object (sc)
The following common properties and methods are available to developers
in the Spark Context sc object version 2+:
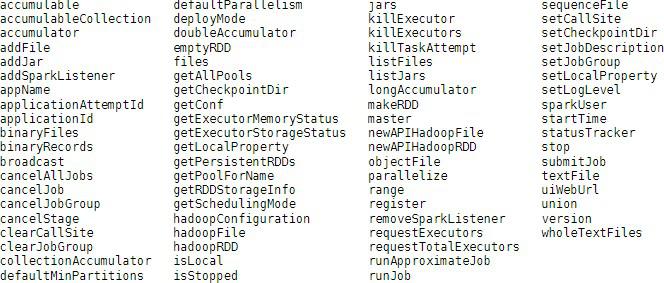
1.8 The Shell Spark Session Object (spark)
The following common properties and methods are available to developers in the Spark Session spark object version 2+:
-

-
Note: The sqlContext object which was also a pre-built object in Spark Shell versions 1.* is now part of the API available through the spark object
-
The org.apache.spark.SparkContext Scala object (aliased in earlier Spark Shells as sc) is available via the sparkContext() method of the org.apache.spark.sql.SparkSession class

1.9 Loading Files
You load a text file (or files) from any of the supported file systems using the textFile (path) method on the Spark Context object:
sc.textFile(path)
The textFile method accepts comma-separated list of files, and a wildcard list of files; you specify the type of the storage using the URI scheme: file:// for local file system, hdfs:// for HDFS, and s3:// for AWS’ S3. Each line in the loaded file(s) becomes a row in the resulting file- based RDD. The sc object also exposes methods for loading other file types: objectFile (Java serialization object format), hadoopFile, and sequenceFile. The spark.read Spark SQL API supports reading files in these formats, csv, jdbc, json, orc, parquet, and text. The resultant object is of type DataFrame.
1.10 Saving Files
The saveAsTextFile(path) method of an RDD reference allows you to write the elements of the dataset as a text file(s). You can save the file on HDFS or any other Spark-supported file system. When saving the file, Spark calls the toString method of each data element to convert it to a line of text in the output file. Methods for saving files in other output file formats:
◊ saveAsSequenceFile (Java & Scala only)
◊ saveAsObjectFile (Java & Scala only)
The DataFrame object offers options for saving its content in these file formats using its write() method, csv, jdbc, json, orc, parquet, and text.
1.11 Summary
Developers have an option to interactively explore and manipulate data using the Spark Shell for Python and for Scala. The Spark Context and Spark Session objects offer developers a rich API for data transformations suitable for data analytics and ETL jobs.