This tutorial is adapted from Web Age course Confluent Kafka for System Administrators.
1.1 Planning for Kafka – Platform
Regarding OS Platforms for Confluent Platform
Linux is the primary platform for deploying Confluent Kafka. macOS is supported for testing/development purposes. Windows is not a supported platform. Confluent Platform can be deployed On-Premises or in cloud environments like AWS, Google Cloud Platform, Azure.
Featured Upcoming
Free Webinars!
Join our community of 80,000 IT professionals by registering today.
AWS Discovery Days – Complimentary
Half Day AWS Training Course
Tuesday, September 28![]()
11:00 AM to 2:30 PM ET
Data Engineering & Data Analytics
Upskilling Trends in 2021
Complimentary White Paper![]()
10 Minute Guide
1.2 Planning for Kafka – OS
Confluent Platform currently supports these Linux OSs:RHEL/CentOS 7.x, Debian 8/9 and Ubuntu 16.04 LST/ 18.04 LTS.
An updated list of supported OSs can be found here:
https://docs.confluent.io/current/installation/versions-interoperability.html#operating-systems
1.3 Planning for Kafka – Java
Confluence Platform runs on Java 8. Java 7 and earlier are no longer supported. Java 9/10 are not supported. The HDFS connector does not support Java 11.
1.4 Planning for Kafka – System Requirements
Confluent Platform can be run for development purposes on a machine with 4GB ram. System requirements for each component of the platform are typically higher for production. For example: Control Center, 300GB storage, 32GB ram, 8 CPU cores or more; Brokers, MultiTB storage, 64GB ram, Dual 12 core cpu; KSQL, SSD storage, 20GB ram, 4 cores.
A complete list of components and requirements can be found here:
http://docs.confluent.io/current/installation/system-requirements.html#on-premise
1.5 Installing Confluent Platform (Kafka)
Confluent can be run on dedicated hardware by installing the platform locally or in the cloud by going to https://confluent.cloud. Confluent can be installed locally from platform packages (installs the entire platform at once) or individual component packages (installs individual components).
1.6 Downloading Confluent Platform
Install images for the Confluent platform can be obtained from the downloads page here:
https://www.confluent.io/download
You can choose to download any of the following formats:
TAR
ZIP
DEB
RPM
DOCKER
1.7 How to set up for Development and Testing?
For development and testing, follow the steps below:
- Setup a VM with SW matching the eventual production environment
- Install Confluent from a Platform install package
- Optionally Confluent can be run from Docker Images
- Confluent Platform can be run from a single terminal using the command:
bin/confluent start
1.8 How to set up for Production?
For Production, follow the steps below:
- Setup a machine or VM for production following the suggested specifications here:
http://docs.confluent.io/current/installation/system-requirements.html#on-premise
- Install Confluent components from individual install packages.
- Run each Confluent component in its own terminal using individual start up scripts.
For example:
bin/kafka-server-start
bin/ksql-server-start - Setup component monitoring and reporting.
- Make adjustments based on actual usage:, ie. Adjust Java heap sizes , Adjust Java garbage collection configuration options.
1.9 Running in Docker Containers
Docker is a technology that enables running of applications inside of ‘Containers’. With Docker, software (like Confluent Platform) can be configured and run inside a container without altering the setup and configuration of the underlying operating system. Containers for Confluent platform components can be created from images available on the DockerHub web site. The Docker software must be installed and the Docker engine running in order to download Docker images and run Docker containers.
Example commands:
docker pull confluentinc/cp-kafka
docker run -d –net=host confluentinc/cp-kafka
Full instructions for running Confluent Platform on Docker can be found here:
https://github.com/confluentinc/cp-docker-images/wiki/Getting-Started
Notes
For a usable installation you will typically need to run at least zookeeper & kafka:
docker run -d \
–net=host \
–name=zookeeper \
-e ZOOKEEPER_CLIENT_PORT=32181 \
-e ZOOKEEPER_TICK_TIME=2000 \
confluentinc/cp-zookeeper
docker run -d \
–net=host \
–name=kafka \
-e KAFKA_ZOOKEEPER_CONNECT=localhost:32181 \
-e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://localhost:29092 \
confluentinc/cp-kafka
1.10 Configuration Files
ZooKeeper
etc/kafka/zookeeper.properties
Kafka
etc/kafka/server.properties
1.11 Starting Kafka
- Start ZooKeeper
bin/zookeeper-server-start etc/kafka/zookeeper.properties - Start Kafka server
bin/kafka-server-start etc/kafka/server.properties - Create a topic
bin/kafka-topics –create –zookeeper localhost:2181 –replication-factor 1 –partitions 1 –topic test
1.12 Using Kafka Command Line Client Tools
- Create a topic (single partition, one replica)
bin/kafka-topics –create –zookeeper localhost:2181 –replication-factor 1 –partitions 1 –topic test - View the created topic(s)
bin/kafka-topics –list –zookeeper localhost:2181 - Send some messages using Kafka producer client
bin/kafka-console-producer –broker-list localhost:9092 –topic test - Read messages by using Kafka consumer client
bin/kafka-console-consumer –bootstrap-server localhost:9092 –topic test –from-beginning
1.13 Setting up a Multi-Broker Cluster
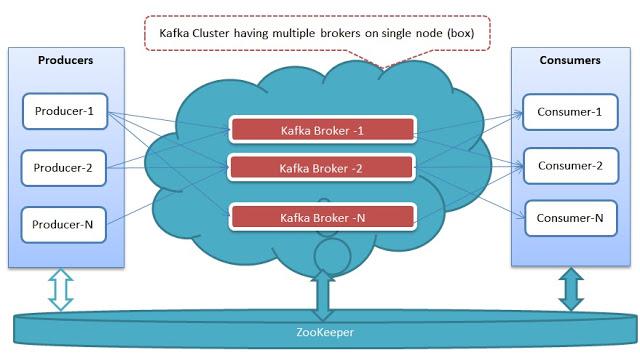
- Create one configuration file per broker
You can duplicate etc/kafka/server.properties and make changes to it - Important configuration attribute values you should modify
broker.id=
listeners=PLAINTEXT://: log.dirs= - Start up multiple brokers
bin/kafka-server-start etc/kafka/.properties
1.14 Using Multi-Broker Cluster
- Create a new topic with replication factor of 3 (just an example)
bin/kafka-topics –create –zookeeper localhost:2181 –replication-factor 3 –partitions 1 –topic my-replicated-topic - Check which broker is doing what, i.e. view brokers used by a topic
bin/kafka-topics –describe –zookeeper localhost:2181 –topic my-replicated-topic
- The above command lists the following important values:
“leader” is the node responsible for all reads and writes for the given partition. Each node will be the leader for a randomly selected portion of the partitions.
“replicas” is the list of nodes that replicate the log for this partition regardless of whether they are the leader or even if they are currently alive.
“isr” is the set of “in-sync” replicas. This is the subset of the replicas list that is currently alive and caught-up to the leader. - Producer and consumer clients are utilized as you saw previously.
- If you terminate a Kafka broker, then Kafka topic “describe” command’s output would look something like this:
bin/kafka-topics –describe –zookeeper localhost:2181 –topic my-replicated-topic
Output:
Topic:my-replicated-topic PartitionCount:1 ReplicationFactor:3 Configs:
Topic: my-replicated-topic Partition: 0 Leader: 2 Replicas: 1,2,0 Isr: 2,0
1.15 Kafka Cluster Planning
When planning a Kafka cluster, the following two areas should be considered:
Sizing for throughput
Sizing for storage
1.16 Kafka Cluster Planning – Producer/Consumer Throughput
Know the expected throughput of your Producer(s) and Consumer(s). The system throughput is as fast as your weakest link. Consider the message size of the produced messages. Know how many consumers would be consuming from the Topics/Partitions. At what rate would the consumer(s) be able to process each message given the message size.
1.17 Kafka Cluster Planning – Number of Brokers (and ZooKeepers)
Increasing the number of brokers and configuring replication across brokers is a mechanism to achieve parallelism and higher throughput.
It also helps to achieve high availability. HA may not be a factor when running Dev and Test environments, but in Production environment, it is strongly recommended to deploy multiple brokers ( 3+). ZooKeeper plays a critical role in the Broker cluster management by keeping track of which brokers are leaving the cluster and tracking which new ones are joining the cluster. Leader election and configuration management is also the responsibility of ZooKeeper. Zookeeper should also be deployed in a HA cluster. The recommendation for sizing your Zookeeper cluster is to use:
1 instance for Dev/Test Environments, 3 instances to plan for 1 node failure and 5 instances to plan for 2 node failures.
1.18 Kafka Cluster Planning – Sizing for Topics and Partitions
The number of partitions depend on the desired throughput and the degree of parallelism that your Producer / Consumer ecosystem can support.
Generally speaking, increasing the # of partitions on a given topic , linearly increases your throughput. The throughput bottleneck could end up being the rate at which your Producer can produce or the rate at which your consumers can consume.
Simple formula to size for topics and partitions:
Lets say the desired Throughput is “t”.
Max Producer throughput is “p”
Max Consumer throughput is “c”.
Number of Partitions = max ( t/p, t/c).
A rule of thumb often used is to have at least as many partitions as the number of consumers in largest consumer group.
1.19 Kafka Cluster Planning – Sizing for Storage
Factors to consider when sizing your storage on a Broker are # Topics, # Partitions per topic, Desired Replication factor, Message Sizes, Retention period and Rate at which messages are expected to be Published and Consumed from Event Hub Broker.
1.20 Kafka Connect
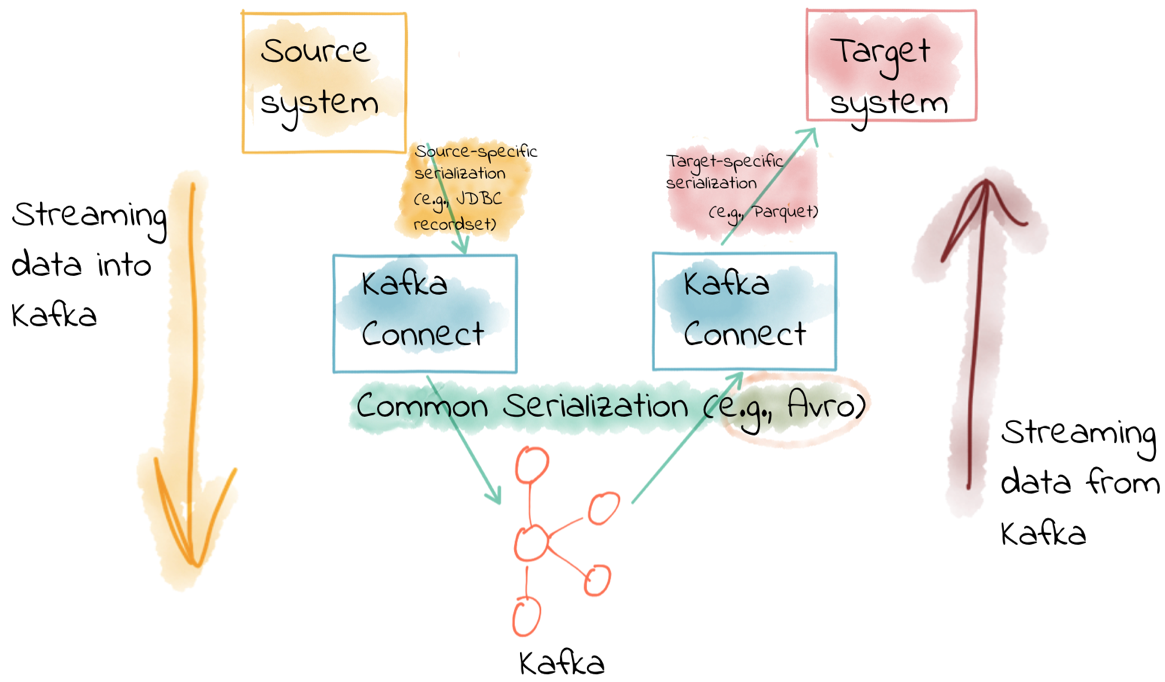 You’ll probably want to use data from other sources or export data from Kafka to other systems. For many systems, instead of writing custom integration code you can use Kafka Connect to import or export data. Kafka Connect is a tool included with Kafka that imports and exports data to Kafka. It is an extensible tool that runs connectors, which implement the custom logic for interacting with an external system.
You’ll probably want to use data from other sources or export data from Kafka to other systems. For many systems, instead of writing custom integration code you can use Kafka Connect to import or export data. Kafka Connect is a tool included with Kafka that imports and exports data to Kafka. It is an extensible tool that runs connectors, which implement the custom logic for interacting with an external system.
1.21 Kafka Connect – Configuration Files
Kafka Connect requires three configuration files as parameters. These files include a unique connector name, the connector class to instantiate, and any other configuration required by the connector.
etc/kafka/connect-standalone.properties – this is the configuration for the Kafka Connect process, containing common configuration such as the Kafka brokers to connect to and the serialization format for data.
etc/kafka/connect-file-source.properties – specifies a file source connector. Data is read from the source file and written to a topic configured in this configuration file.
 etc/kafka/connect-file-sink.properties – specifies file sink connector. Data is read from a topic and written to a text file specified in the configuration.
etc/kafka/connect-file-sink.properties – specifies file sink connector. Data is read from a topic and written to a text file specified in the configuration.
 1.22 Using Kafka Connect to Import/Export Data
1.22 Using Kafka Connect to Import/Export Data
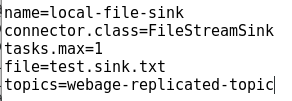
- Start Kafka Connect
bin/connect-standalone etc/kafka/connect-standalone.properties etc/kafka/connect-file-source.properties etc/kafka/connect-file-sink.properties - Use Kafka producer and consumer and verify data is written to a topic and to a file specified in the configuration files.
1.23 Summary
Apache Kafka comes with default configuration files which you can modify to support single or multi-broker configuration. Apache Kafka comes with client tools, such as producer, consumer, and Kafka Connect. You can utilize Apache Kafka in various development tools/frameworks, such Spring Boot, Nodejs etc.