This tutorial is adapted from the Web Age course Operational Data Analytics with Splunk.
1.1 Splunk Defined
1.2 Splunk Products
- Splunk is offered as two main products:
- Splunk Enterprise, and
- Splunk Cloud (a SaaS solution)
Both products provide event and data collection, search, and visualizations for various use cases in IT operations and some security use cases. Splunk’s capabilities are extendable through custom “Apps” for use-case and vendor-specific functionality that are supported through a wide ecosystem of technology partners.
1.3 The Magic Quadrant for Security Information and Event Management (SIEM)
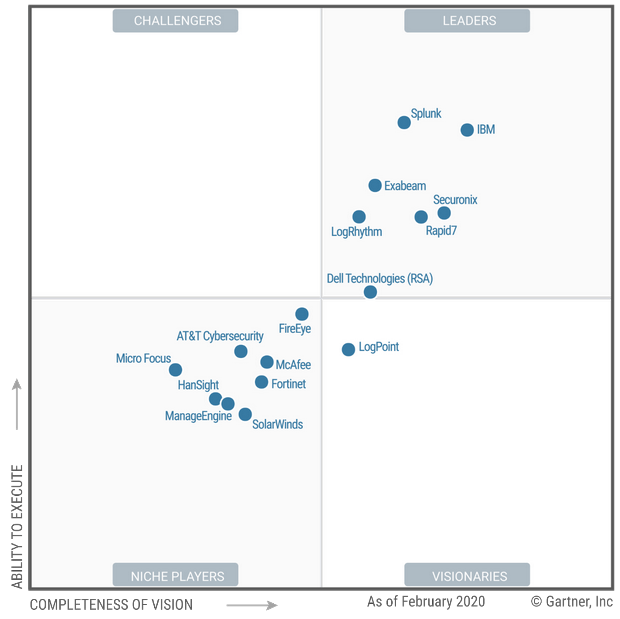 Source: https://www.gartner.com/doc/reprints?id=1-1YEDHXVD&ct=200219&st=sb
Source: https://www.gartner.com/doc/reprints?id=1-1YEDHXVD&ct=200219&st=sb
1.4 Splunk Editions
- The Splunk platform comes in three editions:
- Splunk Enterprise
- Splunk Cloud
- Splunk Free
- Splunk Platform Feature & Comparison Chart of the three editions can be found here: https://www.splunk.com/en_us/software/features-comparison-chart.html
1.5 Deployment Options
- You can deploy Splunk in a variety of scenarios:
- On-premise
- IaaS
- As a hybrid solution
1.6 Common Components
- Both Splunk Enterprise and Splunk Cloud include the following components:
- Universal Forwarder – Lightweight Splunk instance that forwards / sends data to another Splunk Server (Indexer) or to a third-party system.
- Indexer – Splunk Enterprise instance that transforms raw data into time-stamped “events”, indexes the data, and places the processed results into an index database; Indexers also support searches.
- Search Head – Used in a distributed search deployment environments, where one Splunk Enterprise instance fronts a set of search peer instances for dispatching user search requests and collecting / merging the search results back to the user.
- A Splunk Enterprise instance can function as both a search head and a search peer.
1.7 Splunk Admin Dashboard (Web UI)
1.8 Events
Most data comes from some sort of log files or other sources of machine data. Every input data record is wrapped into an event that, in addition to the original raw data, also holds a timestamp, host, source, and source type attributes. The timestamp attribute is either derived from the original record data or, if it is not possible, auto-generated and assigned by Splunk. A glossary of Splunk-specific technical terminology with links to related information can be found here: https://docs.splunk.com/Splexicon.
1.9 Data Indexing
Input machine data records that have been transformed into events are indexed to enable fast search and analysis. Index is a flat file repository for the data. Data within an index is organized as a set of directories called buckets. Typically, an index is a collection of several buckets. Events are stored in an index as a group of files that fall into two categories:
- Raw (the original) data, which is stored in a compressed format
- Index files, which include metadata associated with the raw data
By default, your data is put into a pre-configured index called main. Splunk also uses other indexes for its own purposes. A Splunk Enterprise instance that indexes data and stores the indexes is called Indexer.
1.10 Distributed Splunk Indexing and Searching
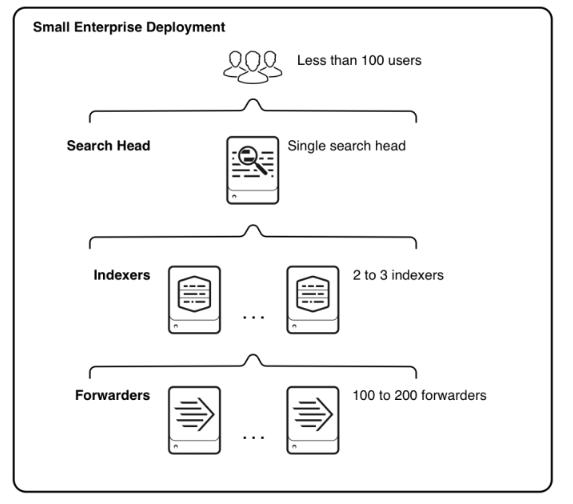
One instance of Splunk Enterprise can handle all aspects of processing data: collection, indexing, and search. Single-instance Splunk deployments, however, are only suitable for low-to-medium load use cases, including prototyping, testing, and Splunk evaluation purposes. More demanding data processing requirements can only be met with larger Splunk indexing and search environments where multiple distributed instances have more specialized roles. A distributed Splunk Enterprise deployment splits the indexing and search management capabilities. For example, one or more instances might only index the data, while another instance would perform searches across the indexed data.
1.11 Architecture for a Multi-Tier Splunk Enterprise Deployment
1.12 Summary
- In this tutorial, we discussed the following topics:
- Splunk products
- Deployment options
- Distributed indexing & searching