1.1 What is Apache Spark?
Apache Spark (Spark) is a general-purpose processing system for large- scale data. Spark is effective for data processing of up to 100s of terabytes on a cluster of machines. It runs on both Unix-like systems and Windows. Main players behind Spark are Apache Software, Databricks (founded by the creators of Spark), UC Berkeley AMPLab, Cloudera, Yahoo, MapR, etc. Please find Spark overview at https://spark.apache.org/docs/latest/.
1.2 A Short History of Spark
It started as a research project at AMPLab at UC Berkeley in 2009. First open sourced in 2010 under a BSD license; in 2013, Spark was donated to the Apache Software Foundation (ASF) and switched its license to Apache 2.0.
1.3 Where to Get Spark?
You can download Apache Spark from web site: https://spark.apache.org/.
Main Hadoop distributors are Cloudera (CDH), Hortonworks (HDP) and MapR. Spark is usually added through forming partnerships with Databricks. You can download and use Hadoop-free Spark bundles.
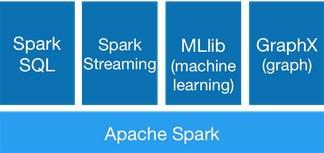
1.4 The Spark Platform
Spark includes specialized libraries for SQL-type data processing (Spark SQL), Machine learning, Graph-parallel computation (GraphX), Near-real time processing of streaming data (Spark Streaming), You can combine these libraries in the same Spark application.
 1.5 Spark Logo
1.5 Spark Logo 1.6 Common Spark Use Cases
1.6 Common Spark Use Cases

-
Extract/Transform/Load (ETL) jobs
-
Data Analysis
◊ Text mining
◊ Predictive analytics
◊ User sentiment analysis
◊ Risk assessment
◊ Graph data analysis
1.7 Languages Supported by Spark
The Spark platform provides API for applications written in Scala, Python, Java, and R. With the Spark SQL library, you can also create applications using SQL interface. Spark does not impose any limitations on supported run-times. For example, Python apps can call into existing Python C libraries. Some additional libraries may be required to be installed. For example, Python API may require you to install the NumPy package. Spark programs can query in-memory data repeatedly which makes Spark making an excellent platform for running machine learning algorithms.
1.8 Running Spark on a Cluster
Spark design is based on the master /slave architecture with a single master and a cluster of slave (worker) nodes. Spark comes with its own (basic) cluster management system allowing it to be deployed as a stand-alone product. Supported run-times must be installed on every machine in the cluster. For external cluster management requirements, Spark can be integrated with Hadoop YARN, The Apache Mesos cluster manager (also developed by UC Berkeley) and Amazon EC2 (via scripts).
1.9 The Driver Process
A running Spark application process is called the “Driver”. The Driver creates the SparkContext object referencing the Master node and acting as the entry point to Spark API. The Driver process communicate with the Master for any required resources. The Spark’s Driver process is conceptually similar to YARN’a Application Master process.
1.10 Spark Applications
Spark applications are programs written in Spark-supported languages (currently, Python, Scala, Java, and R). Developing and running Spark applications require developers to attend to the following details:
◊ Compiling applications and building the JAR (Java ARchive) file (this step only applies to Scala and Java — not to Python or R)
◊ Creating the SparkContext object
◊ Submitting the application JAR file (or Python or R program) for execution
1.11 Spark Shell
The Spark shell is a command-line interactive development environment which simplifies development work. The SparkContext object is configured and made available to the developer automatically when the shell starts. The shell executes every command as it is entered. The Spark shell only supports Python and Scala (Java is not supported yet). The Python Spark Shell (PySpark) is launched by the pyspark command. The Scala Spark Shell is launched by the spark-shell command. SparkR shell was added recently to support development of R applications. SparkR Shell has only been thoroughly tested to work with Spark standalone so far and not all Hadoop distros available, and therefore is not covered here. The shell is also referred to as REPL (Read/Eval/Print Loop).
1.12 The spark-submit Tool
The spark-submit command-line tool is the standard way of submitting Spark applications for execution.
Submitting Scala and Java Spark application JAR file:
spark-submit <config options> –class <Your class with the main method> <YourJarFile.jar> <The list of program arguments>
-
Submitting Python Spark applications (regular Python programs):
spark-submit<config options> <Your Python program> <The list of program arguments>
1.13 The spark-submit Tool Configuration
-
The main spark-submit configuration option is the —master parameter which specifies the cluster management master (if any) and may have the following values:
◊ local – your app will run locally using all CPU cores (the default value)
◊ local – your app will run locally using n threads (may be sub-optimal)
◊ <master URL> – pointing to the cluster management master URL, e.g.
-
spark://<master IP>:7077 – a Spark native cluster
-
mesos://<master IP>:7077 – a Mesos cluster
-
yarn – a YARN cluster
-
For example:
spark-submit –class was.labs.spark.JavaOnSpark
–master spark://master.com:7077 JavaOnSpark.jar
◊ Note: You can similarly to the above configure spark-shell and pyspark shells
-
You can also reserve (aggregate) memory for your application using the
–executor-memory configuration parameter, e.g.
–executor-memory 32G
Notes:
Here is the complete list of the supported spark-submit configuration properties (as of version 1.6) obtained using the spark-submit –help command:
Note: Whenever you see the [spark://…] prefix, the run-time context is Spark stand-alone, which may not necessarily be supported on Hadoop (YARN).
$ spark-submit –help
Usage: spark-submit <app jar | python file> [app arguments] Usage: spark-submit –kill –master [spark://…] Usage: spark-submit –status –master [spark://…]
Options:
–master MASTER_URL spark://host:port, mesos://host:port, yarn, or local.
–deploy-mode DEPLOY_MODE Whether to launch the driver program locally (“client”) or
on one of the worker machines inside the cluster (“cluster”) (Default: client).
–class CLASS_NAME Your application’s main class (for Java / Scala apps).
–name NAME A name of your application.
–jars JARS Comma-separated list of local jars to include on the driver
and executor classpaths.
–packages Comma-separated list of maven coordinates of jars to include on the driver and executor classpaths. Will search the local maven repo, then maven central and any additional remote repositories given by –repositories. The format for the coordinates should be groupId:artifactId:version.
–exclude-packages Comma-separated list of groupId:artifactId, to exclude while
resolving the dependencies provided in –packages to avoid dependency conflicts.
–repositories Comma-separated list of additional remote repositories to
search for the maven coordinates given with –packages.
–py-files PY_FILES Comma-separated list of .zip, .egg, or .py files to place
on the PYTHONPATH for Python apps.
–files FILES Comma-separated list of files to be placed in the working directory of each executor.
–conf PROP=VALUE Arbitrary Spark configuration property.
–properties-file FILE Path to a file from which to load extra properties. If not
specified, this will look for conf/spark-defaults.conf.
–driver-memory MEM Memory for driver (e.g. 1000M, 2G) (Default: 1024M).
–driver-java-options Extra Java options to pass to the driver.
–driver-library-path Extra library path entries to pass to the driver.
–driver-class-path Extra class path entries to pass to the driver. Note that
jars added with –jars are automatically included in the classpath.
–executor-memory MEM Memory per executor (e.g. 1000M, 2G) (Default: 1G).
–proxy-user NAME User to impersonate when submitting the application.
–help, -h Show this help message and exit
–verbose, -v Print additional debug output
–version, Print the version of current Spark
Spark standalone with cluster deploy mode only:
–driver-cores NUM Cores for driver (Default: 1).
Spark standalone or Mesos with cluster deploy mode only:
–supervise If given, restarts the driver on failure.
–kill SUBMISSION_ID If given, kills the driver specified.
–status SUBMISSION_ID If given, requests the status of the driver specified.
Spark standalone and Mesos only:
–total-executor-cores NUM Total cores for all executors.
Spark standalone and YARN only:
–executor-cores NUM Number of cores per executor. (Default: 1 in YARN mode,
or all available cores on the worker in standalone mode)
YARN-only:
–driver-cores NUM Number of cores used by the driver, only in cluster mode
(Default: 1).
–queue QUEUE_NAME The YARN queue to submit to (Default: “default”).
–num-executors NUM Number of executors to launch (Default: 2).
–archives ARCHIVES Comma separated list of archives to be extracted into the
working directory of each executor.
–principal PRINCIPAL Principal to be used to login to KDC, while running on
secure HDFS.
–keytab KEYTAB The full path to the file that contains the keytab for the
principal specified above. This keytab will be copied to the node running the Application Master via the Secure Distributed Cache, for renewing the login tickets and the delegation tokens periodically.
1.14 The Executor and Worker Processes
The Master allocates resources on the Worker nodes in the cluster and Driver’s jobs/tasks are processed by Executor processes allocated on the Worker nodes. A Spark job consists of multiple tasks. The Executor processes correspond to YARN’s Containers. An Executor process can run multiple tasks and has a built-in cache. Executor processes are started by Workers running on the same machine. Basically, your Spark application consists of your Driver program and Executor processes running on the cluster.
1.15 The Spark Application Architecture

1.16 Interfaces with Data Storage Systems
Spark can be integrated with a wide variety of distributed storage systems like Hadoop Distributed File System (HDFS), Amazon S3 and OpenStack Swift etc. Spark understands Cassandra, HBase and any Hadoop’s data formats. For standalone Spark deployments, you can use NFS mounted at the same path on each node as a shared file system mechanism. Spark also supports a pseudo-distributed local mode running on a single machine where the local file system can be used instead of a distributed storage; this mode is only used for development or testing purposes.
1.17 Limitations of Hadoop’s MapReduce
Hadoop’s MapReduce processing model is not always efficient.Generally, the complaint is about its inherent processing latencies. Hadoop’s MapReduce (MR) is designed as a fault-tolerant system heavily dependent on disk to persist intermediate results of MR jobs. This architecture is sometimes described as a disk-based system design. The MR engine executes jobs arranged in a Directed Acyclic Graph (DAG) which prevents cost-efficient execution of applications that require multi- pass flow (such flows can benefit from passing temp results through shared memory of the same run-time resource). Data processing in MR is acyclic and the processing flow is based on running a series of distinct jobs that can share data. In other words, Hadoop’s MR is, by design, inefficient for multi-pass applications.
1.18 Spark vs MapReduce
Spark offers ~ 100X (in best for Spark multi-pass cases!) faster processing than Hadoop MR, or ~10X faster if intermediate results are committed to disk. Spark achieves these efficiencies by re-using already loaded JVM (the heap is shared between related processes), data set caching and if a data set does not fit in memory, the data is spilled over to disk (with an unavoidable negative performance impact).
1.19 Spark as an Alternative to Apache Tez
The Apache Tez project (https://tez.apache.org/) aims at boosting Hadoop’s MR performance and optimizing resource utilization. Basically, Tez coalesces multiple MR jobs in a single Tez job which offers overall application performance improvement. Projects are under way to make Apache Pig and Hive run on Spark as an alternative to Tez execution engine.
1.20 The Resilient Distributed Dataset (RDD)
A Resilient Distributed Dataset (RDD) is the fundamental abstraction in Spark representing data partitioned across machines in a Spark cluster. RDDs are resilient against data loss (can be re-created / re-computed) and distributed across the cluster (stored in workers’ memory). Spark APIs are centered around RDD processing.
1.21 Datasets and DataFrames
Spark 1.6 added a new distributed collection of data – Dataset. A Dataset object can be manipulated using transformations like map, flatMap, filter, etc. The Dataset API is available in Scala and Java. Python does not have the native support for the Dataset API and has to un/marshal data between Python runtime and JVM. A DataFrame is a Dataset with named columns. The DataFrame API is available in Scala, Java, Python, and R. DataFrames can be constructed from such sources as: CSV, JSON or other file formats; Hive tables; external databases; existing RDDs. The DataFrame-based API is now the primary and recommended structured data processing API in Spark Machine learning projects.
1.22 Spark Streaming (Micro-batching)
Spark supports near-real time ( under 0.5 second latencies) streaming data processing. Spark uses a micro-batch execution model based on discretized streams where incoming data is collected over a time window (e.g. 10 seconds). Micro-batching supports consistent exactly-once (no duplicates) semantics where Spark can recover all intermediate state in case of a data loss. Spark Streaming model enables code re-use, where programs written for regular batch analytics can be (with little changes) used in micro-batching scenarios.
1.23 Spark SQL
The Spark SQL module provides a mechanism for mixing SQL-based queries with Spark programs written in Scala, Python, R, and Java. As of Spark version 1.3, the original term used to describe the Spark SQL RDD type, SchemaRDD, was renamed to DataFrame. Spark has tight integration with Hive. It can use Hive’s metastore, SerDes codecs and User-defined functions. Spark SQL is also used to read and write data in a variety of file formats (CSV, JSON, Avro, OCR, and Parquet). Spark can run in server mode that offers connectivity to ODBC/JDBC clients (the feature normally used by BI tools to query Big Data fronted by Spark).
1.24 Example of Spark SQL
sqlCtx = new SQLContext(…)
results = sqlCtx.sql( “SELECT * FROM BigDataTable”) errorRecords=results.filter(r=>r.code.contains(“error”))
1.25 Spark Machine Learning Library
Spark Machine Learning Library runs on top of Spark and takes full advantage of Spark’s distributed in-memory design. Spark ML developers claim 10X faster performance for similar applications created using Apache Mahout running on Hadoop via the MR engine. Spark ML library implements a whole suite of statistical and machine learning algorithms.
1.26 GraphX
GraphX is Apache Spark’s API for graphs and graph-parallel computation. GraphX started initially as a research project at UC Berkeley AMPLab and Databricks, and was later donated to the Spark project. It provides comparable performance to common graph processing systems, e.g. Giraph.
 Source: https://spark.apache.org/graphx/.
Source: https://spark.apache.org/graphx/.
1.27 Spark vs R
R is an interpreted single-threaded language. R runs on a single machine. You can collaborate with other users using RStudio Server. 64-bit architectures are supported. 2G+ RAM can be allocated for large data sets. Spark can give you a choice of faster languages (Java, Scala). It is optimized for speed (local / external (Tachyon-based) caching, etc.). Spark allows you to run Machine Learning (ML) apps on a cluster of machines. R gives developers a richer choice and variations of supported statistical and ML algorithms.
1.28 Summary
Spark is a general-purpose processing system for large-scale data on a cluster of machines. It is used in a wide variety of applications like Extract/Transform/Load (ETL) jobs and Data Analysis. Spark applications are written in Scala, Python, Java, or R. Spark offers between 10X to 100X faster processing times than Hadoop MapReduce. A Resilient Distributed Dataset (RDD) is the main data unit in Spark which represents data partitioned across machines in the cluster. Spark supports Streaming API, mixed SQL processing model, and a wide range of Machine Learning and Graph processing algorithms.